引言
本系列的课程来源是 斯坦福大学公开课 CS229: 机器学习课程,也可以看网易公开课的资源,是带字幕的。斯坦福的 CS229 课程相比于 Course 上的 Machine Learning 课程,理论更强,讲解的也更深入,需要有一些的高数基础。两个课程都看了前半部分,更推荐前者,所以相关笔记对应的都是 CS229 课程。
线性回归的定义
适用于监督学习,根据已有的数据集合(x, y),来推断出将来的数据趋势。
单变量线性回归
最后的函数应该是 y = ax + b,假设 hypothesis 为:
则问题转化为求 $\theta_{0}$ 和 $\theta_{1}$ 的值。要求这两个值需要转化上式,并根据已有的数据来求解。下面介绍损失函数,又叫代价函数的概念。
Cost Function
针对每一组数据,公式的值是 $h_{\theta}$($x_{i}$), 实际的值是 $y_{i}$,我们要达到的效果则是公式能够尽量表达已有的 m 组数据集合,即 $( h_{\theta}(x^{(i)}) - y_{i})^{2}$ 的值尽量小。
所以,对于所有数据集合,需要求使得
我们需要最小化这个 Cost Function。
Cost Function 的作用
假设 $\theta_0$ = 0,则有 $\theta_1$ 和 J($\theta_1$) 的关系,且图形如下: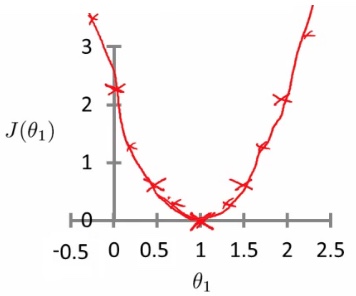
所以当 $\theta_1$ = 1 时,
很容易看出,$J(\theta_1)$ 是关于 $\theta_1$ 的一元二次方程,对于所有的训练数据,每个 $\theta_1$ 的取值都会得到一个 $J(\theta_1)$ 值,而 $J(\theta_1)$ 和 $\theta_1$ 的对应关系根据一元二次方程可知,函数曲线如上图。
当 $J(\theta_1)$ 最小时,求得 $\theta_1$ 结果。
当 $\theta_0$ 和 $\theta_1$ 都不为 0 时,J($\theta_0$, $\theta_1$) 的图形如下: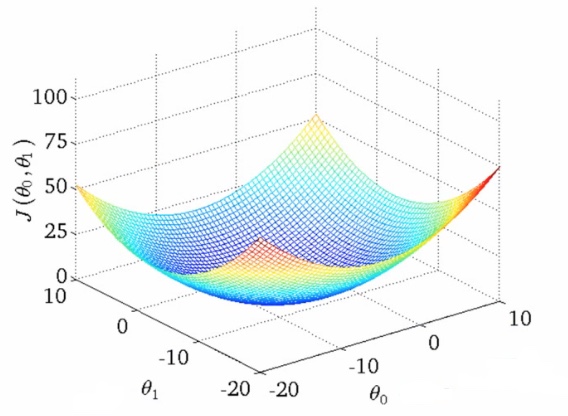
对于两个系数的情况不如一个系数是一个二维坐标系的抛物线那么简单。下面将介绍梯度下降法。
梯度下降法
- Start with initial guesses
- Start at 0,0 (or any other value)
- Keeping changing $\theta_0$ and $\theta_1$ a little bit to try and reduce J($\theta_0$, $\theta_1$)
- Each time you change the parameters, you select the gradient which reduces J($\theta_0$, $\theta_1$) the most possible
- Repeat
- Do so until you converge to a local minimum
Has an interesting property- Where you start can determine which minimum you end up
- Here we can see one initialization point led to one local minimum
- The other led to a different one
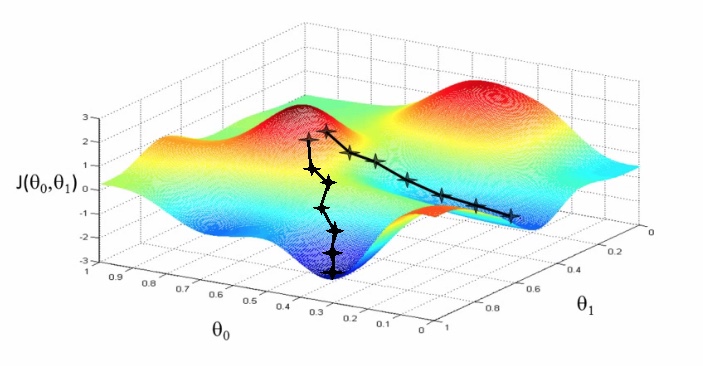
具体的计算过程
(for j = 0 and j = 1)
Notation
$\alpha$
- Is a number called the learning rate
- Controls how big a step you take
- If α is big have an aggressive gradient descent
- If α is small take tiny steps
- Too small
- Take baby steps
- Takes too long
- Too large
- Can overshoot the minimum and fail to converge
Computer
每次都是同时计算 $\theta_0, \theta_1$ 的值,如下:
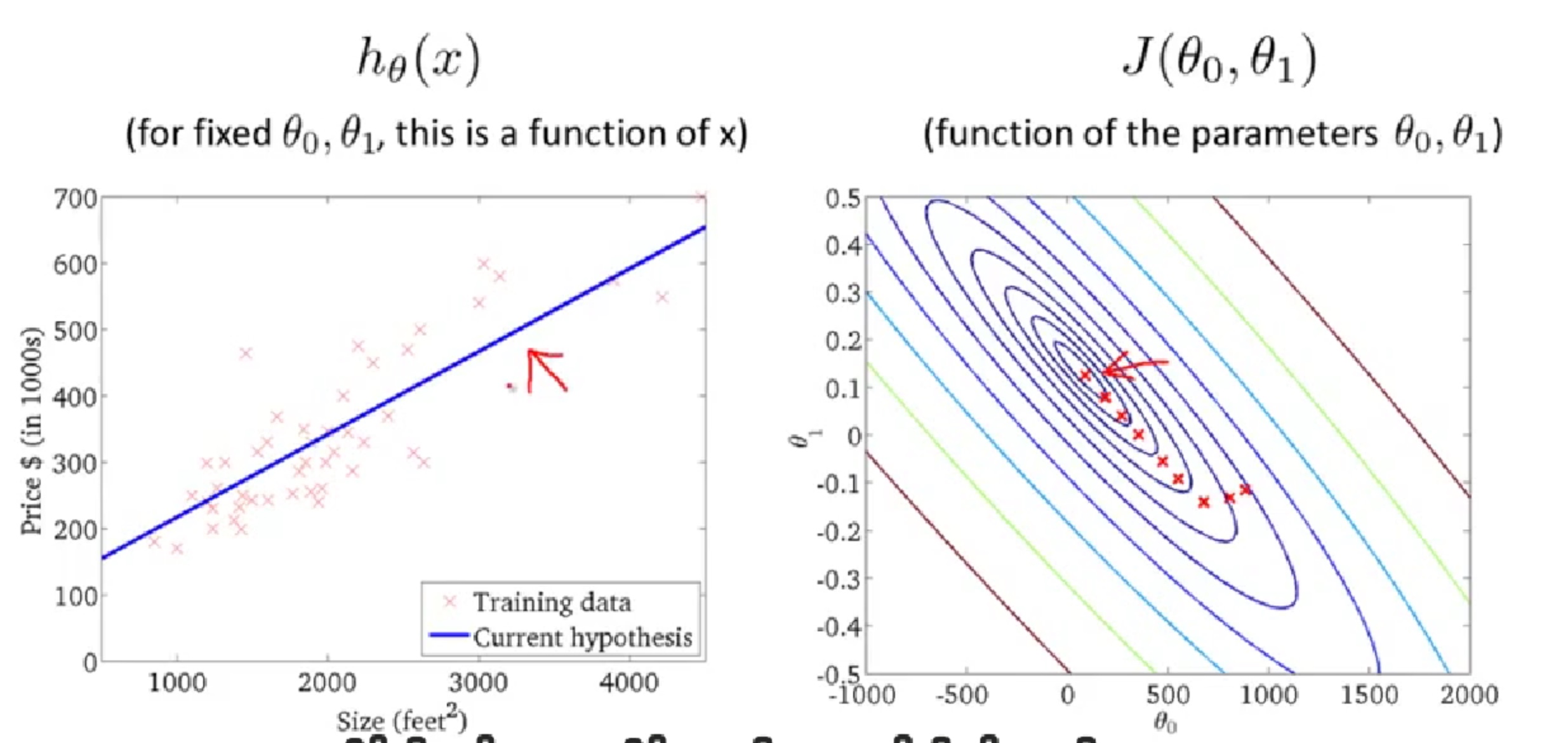
利用梯度下降法求解线性回归问题
对于 j = 0 or 1 的情况有:
j = 0:
j = 1:
梯度下降法的证明
1、如果优化函数存在解析解。例如我们求最值一般是对优化函数求导,找到导数为0的点。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数。
2、如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,互相依赖的情况。或者求导后式子得不到解释解,或者未知参数的个数大于方程组的个数等。这时候使用迭代算法来一步一步找到最优解。
- 当目标函数是凸函数时,梯度下降法的解是全局最优解
- 一般情况下,其解不保证是全局最优解
凸函数
凸函数就是一个定义在某个向量空间的凸子集C(区间)上的实值函数 f,而且对于凸子集C中任意两个向量 $x_1$, $x_2$ 有:
于是容易得出对于任意(0,1)中有理数 p,有:
如果 f 连续,那么 p 可以改成任意(0,1)中实数。则 f 称为 I 上的凸函数,当且仅当其上境图(在函数图像上方的点集)为一个凸集。
梯度下降法的使用
我们首先在函数上任选一点,计算其损失(即我们上面的L(w)) ,然后按照某一规则寻找更低的一点计算新的损失,只要新损失更小(最小化问题),我们就继续下降,直到达到一个可接受的优化目标。
梯度下降方法分为两个部分,第一部分是整体上,我们使用某步长不断下降求损失函数,第二部分是为了防止步长太长导致最后无法收敛,每次当损失上升的时候都调整步长。
通常实践中使用时,都是用一些开源算法,很少需要深度改进,比如使用 libsvm 可以直接求解逻辑回归。
Reference
http://www.cnblogs.com/yysblog/p/3268508.html
http://52opencourse.com/125/coursera%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%94%E8%AE%B0-%E6%96%AF%E5%9D%A6%E7%A6%8F%E5%A4%A7%E5%AD%A6%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AC%AC%E5%85%AD%E8%AF%BE-%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92-logistic-regression
http://www.cnblogs.com/chaoren399/p/4851658.html
